MapReduce Introduction
In this section, we will learn about MapReduce, its different phases and terminologies.
- Split:

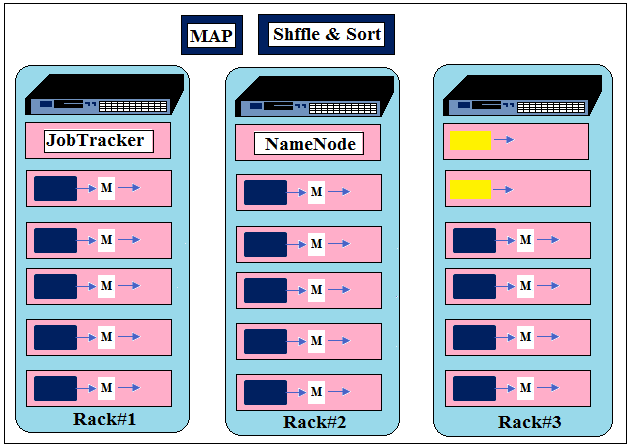
The logical chunk of data that serves as input to map task. In the snapshot given below blue rectangles represent splits. - Block:physical data stored in HDFS. Default block size is 64 MB but it can be configured to 128 MB or 256 MB.Blocks and splits are two different stuff: block belongs to HDFS and split belongs to MapReduce.
- Map Tasks
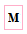
Map tasks process the splits and produce the output. In the snapshot given below M represent Map tasks. - Map Outputs

In general, a map tasks process a large chunk of data (64 MB default) and produce small chunk as output in a good case. Map output can be equal or even larger than the input file but it’s not a good case. In the snapshot given below the smaller yellow rectangles represent map tasks outputs.

- Shuffled and Sorted Data

Map outputs are shuffled, sorted and merged together in a file. This output would be fed to Reducer as input.

- Reduce Task

Reducer process the shuffled and sorted data and produce the final result. There can be single or more Reducer or even no Reducer in a MapReduce Job. - Final Result

After the completion all Reduce tasks, results save on HDFS or local disk in case of standalone mode.
When you think of MapReduce job, the job is divided into two parts: Map part and Reduce part. The Map part consists of several map tasks and Reduce part also consists of several Reduce tasks. All the Map tasks run in parallel and produce output according to the logic given in the map method. All these outputs, produced by map tasks, are shuffled, sorted and merged into a file which serves input to the Reduce job. The Reduce tasks take this as input and produce the final results according to the logic given in the reduce method of source code. In case of more than one reducer, the reduce tasks also run in parallel.
- JobTracker and TaskTracer
The whole execution is controlled by two nodes- JobTracker and TaskTracker in case of classic MapReduce.
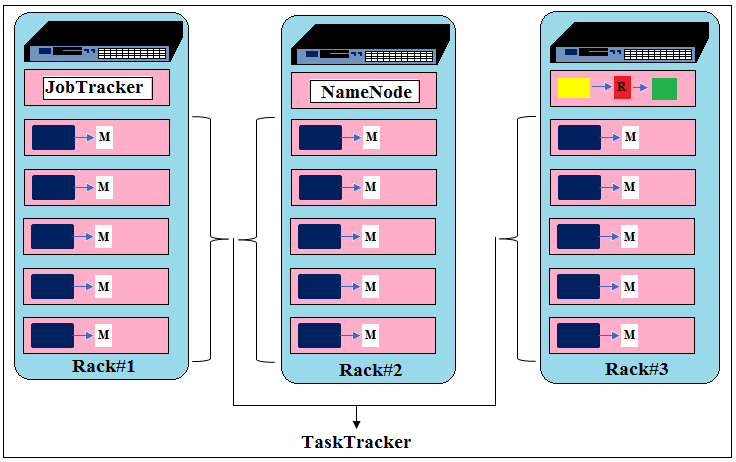
JobTrackers manage scheduling tasks to be run on TaskTracers. TaskTracker runs the Map and Reduce tasks and send the progress to JobTracer.
Phases in Details
In the MapReduce programming, we need to break up the problem into two phases: first is the map phase and second is the reduce phase. We need to code the functionality of map method and reduce method respectively. The Map works on the data that is stored on the node itself and this principle is known as data locality.
It is important that the map phase get their input which is local and if this is not a case, data would need to fetch from the network by the Hadoop framework. This data fetching would increase the network input/output overhead and hence the overall performance would be degraded. Hence the optimal value of split size should be equal to the block size as one complete block would present on one node and thus every map would have a split located on its local storage. A single split is processed by a single Map task so the total number of input splits decide the total number of Map tasks for a MapReduce job.
Map Phase
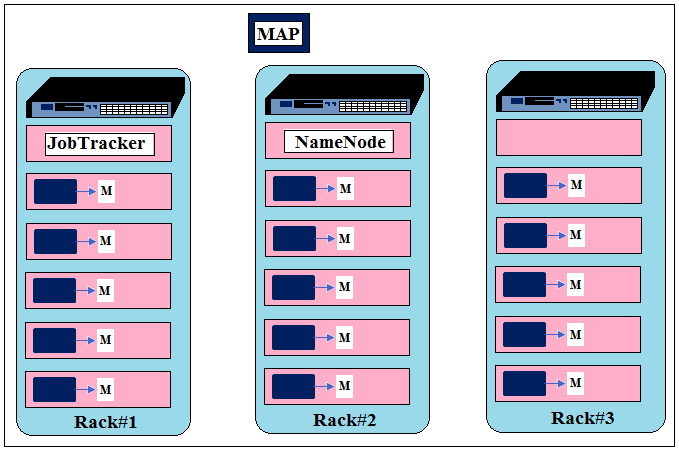
Map tasks, after successful processing, write out their output on the local disk, not on the HDFS. This output is also called as Intermediate Data. This Intermediate Data has no importance after the final result has been calculated i.e., after the execution of Reduce task. It is being stored only until the time Reducer has picked up and processed it successfully. It happens so that Reduce may get fail during processing and in that case, JobTracer would reuse the Intermediate Data. JobTracer cleans up the Intermediate Data only after the completion of the job.
In case when the number of reduce task set as 0, map output is written on HDFS. In this case, the Map’s output will be the final result of the job and the final result has to store on HDFS as it increases the resistance to loss because of hardware failure.
Shuffle & Sort
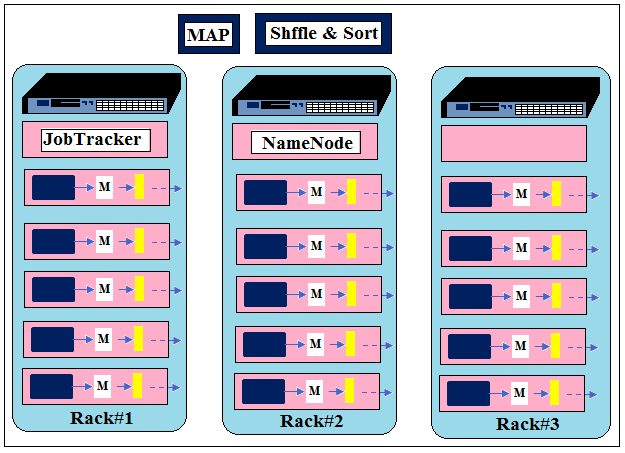
This phase is done by Hadoop Framework itself. In this phase all the Map outputs are merged, sorted and partitioned. So there are three steps that have happened:
- Merge: which combines the output of all the Map tasks.
- Sort: sorts the Map data based on the key.
- Partition: output will be divided based on the hash code of the key.
We will discuss these steps in details later in the course.
Reduce Phase

Reducer doesn’t get data locally it fetches the data from the network. The number of Reducers is not decided by the input size fed to them likewise Map. The number of Reducers decided independently. Reducer output is written to HDFS with replication for reliability.